About me: My name is Solène Rapenne, pronouns she/her. I like learning and
sharing knowledge. Hobbies: '(Qubes OS BSD OpenBSD Lisp cmdline gaming security QubesOS internet-stuff). I
love percent and lambda characters. Qubes OS core team member, former OpenBSD developer solene@. No AI is involved in this blog.
Contact me: solene at dataswamp dot org or
@solene@bsd.network (mastodon).
Let's continue my series trying to design a NixOS fleet management.
Yesterday, I figured out 3 solutions:
periodic data checkout
pub/sub - event driven
push from central management to workstations
I retained solutions 2 and 3 only because they were the only providing instantaneous updates. However, I realize we could have a hybrid setup because I didn't want to let the KISS solution 1 away.
In my opinion, the best we can create is a hybrid setup of 1 and 3.
In this setup, all workstations will connect periodically to the central server to look for changes, and then trigger a rebuild. This simple mechanism can be greatly extended per-host to fit all our needs:
periodicity can be configured per-host
the rebuild service can be triggered on purpose manually by the user clicking on a button on their computer
the rebuild service can be triggered on purpose manually by a remote sysadmin having access to the system (using a VPN), this partially implements solution 3
the central server can act as a binary cache if configured per-host, it can be used to rebuild each configuration beforehand to avoid rebuilding on the workstations, this is one of Cachix Deploy arguments
using ssh multiplexing, remote checks for the repository can have a reduced bandwidth usage for maximum efficiency
a log of the update can be sent to the sftp server
the sftp server can be used to check connectivity and activate a rollback to previous state if you can't reach it anymore (like "magic rollback" with deploy-rs)
the sftp server is a de-facto available target for potential backups of the workstation using restic or duplicity
The mechanism is so simple, it could be adapted to many cases, like using GitHub or any data source instead of a central server. I will personally use this with my laptop as a central system to manage remote servers, which is funny as my goal is to use a server to manage workstations :-)
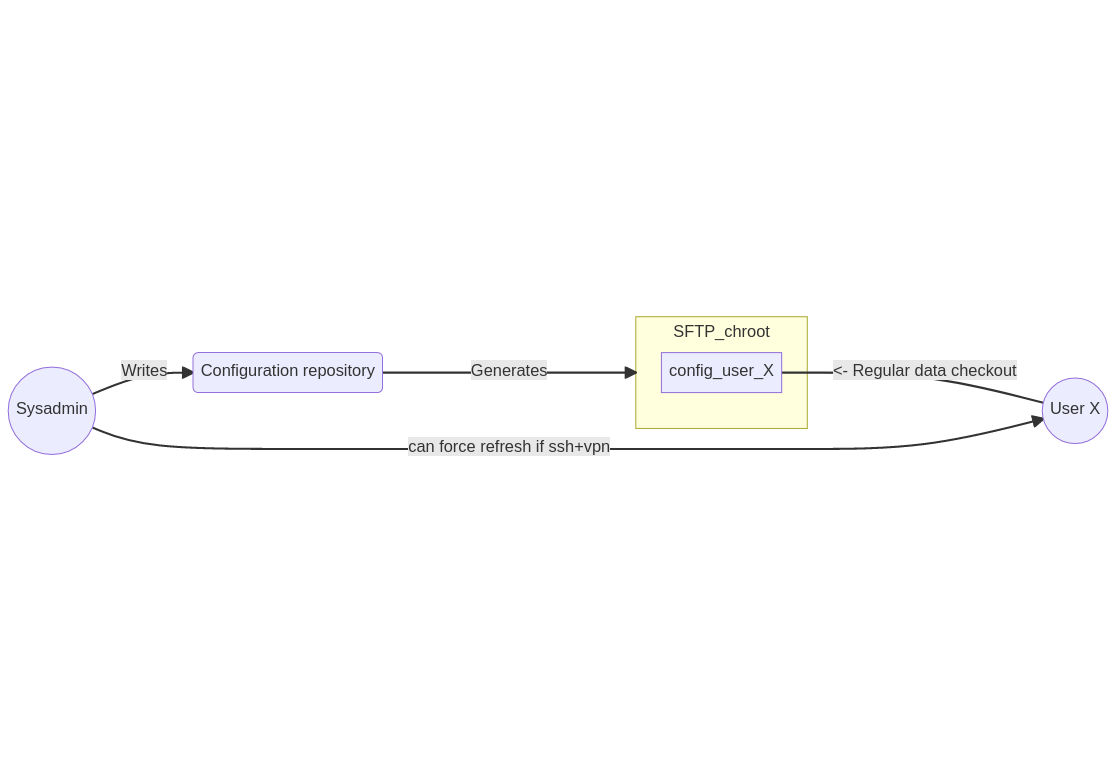
the sysadmin writes configuration files for each workstation in a dedicated directory
the sysadmin creates a symlink to a directory of common modules in each workstation directories
after a change, the sysadmin runs a program that will copy each workstation configuration into a directory in a chroot, symlinks have to be resolved
OPTIONAL: we can dry-build each host configuration to check if they work
OPTIONAL: we can build each host configuration to provide them as a binary cache
The directory holding configuration is likely to have a flake.nix file (can be a symlink to something generic), a configuration file, a directory with a hierarchy of files to copy as-this in the system to copy things like secrets or configuration files not managed by NixOS, and a symlink to a directory of nix files factorized for all hosts.
The NixOS clients will connect to their dedicated users with ssh using their private key, this allows to separate each client on the host system and restrict what they can access using the SFTP chroot feature.
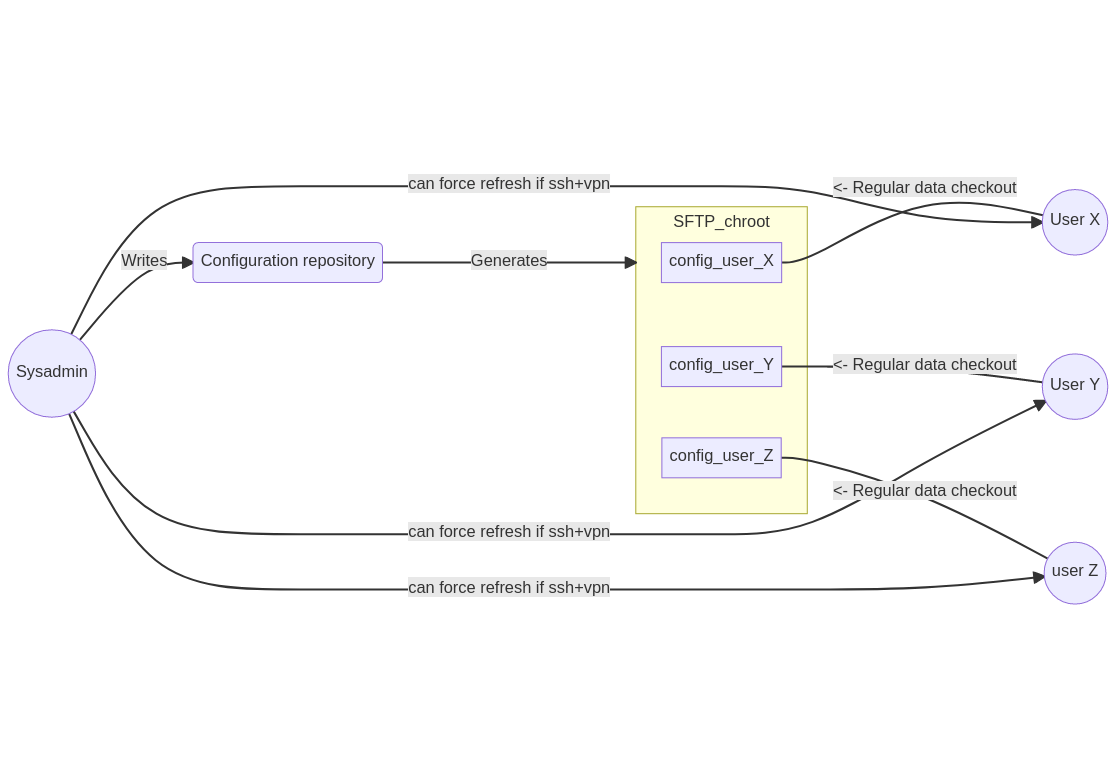
A diagram of a real world case with 3 users would look like this:
The setup is very easy and requires only a few components:
a program to translates the configuration repository into separate directories in the chroot
some NixOS configuration to create the SFTP chroots, we just need to create a nix file with a list of pair of values containing "hostname" "ssh-public-key" for each remote host, this will automate the creation of the ssh configuration file
a script on the user side that connects and look for changes and run nixos-rebuild if something changes, maybe rclone could be used to "sync" over SFTP efficiently
a systemd timer for the user script
a systemd socket triggering the user script, so people can just open http://localhost:9999 to trigger the socket and forcing the update, create a bookmark named "UPDATE MY MACHINE" on the user system
I absolutely love this design, it's simple, and each piece can easily be replaced to fit one's need. Now, I need to start writing all the bits to make it real, and offer it to the world 🎉.
There is a NixOS module named autoUpgrade, I'm aware of its existence, but while it's absolutely perfect for the average user workstation or server, it's not practical for managing a fleet of NixOS efficiently.