About me: My name is Solène Rapenne, pronouns she/her. I like learning and
sharing knowledge. Hobbies: '(Qubes OS BSD OpenBSD Lisp cmdline gaming security QubesOS internet-stuff). I
love percent and lambda characters. Qubes OS core team member, former OpenBSD developer solene@. No AI is involved in this blog.
Contact me: solene at dataswamp dot org or
@solene@bsd.network (mastodon).
Hello 👋🏻, it's been a long time I didn't have to take a look at monitoring servers. I've set up a Grafana server six years ago, and I was using Munin for my personal servers.
However, I recently moved my server to a small virtual machine which has CPU and memory constraints (1 core / 1 GB of memory), and Munin didn't work very well. I was curious to learn if the Grafana stack changed since the last time I used it, and YES.
There is that project named Prometheus which is used absolutely everywhere, it was time for me to learn about it. And as I like to go against the flow, I tried various changes to the industry standard stack by using VictoriaMetrics.
In this article, I'm using NixOS configuration for the examples, however it should be obvious enough that you can still understand the parts if you don't know anything about NixOS.
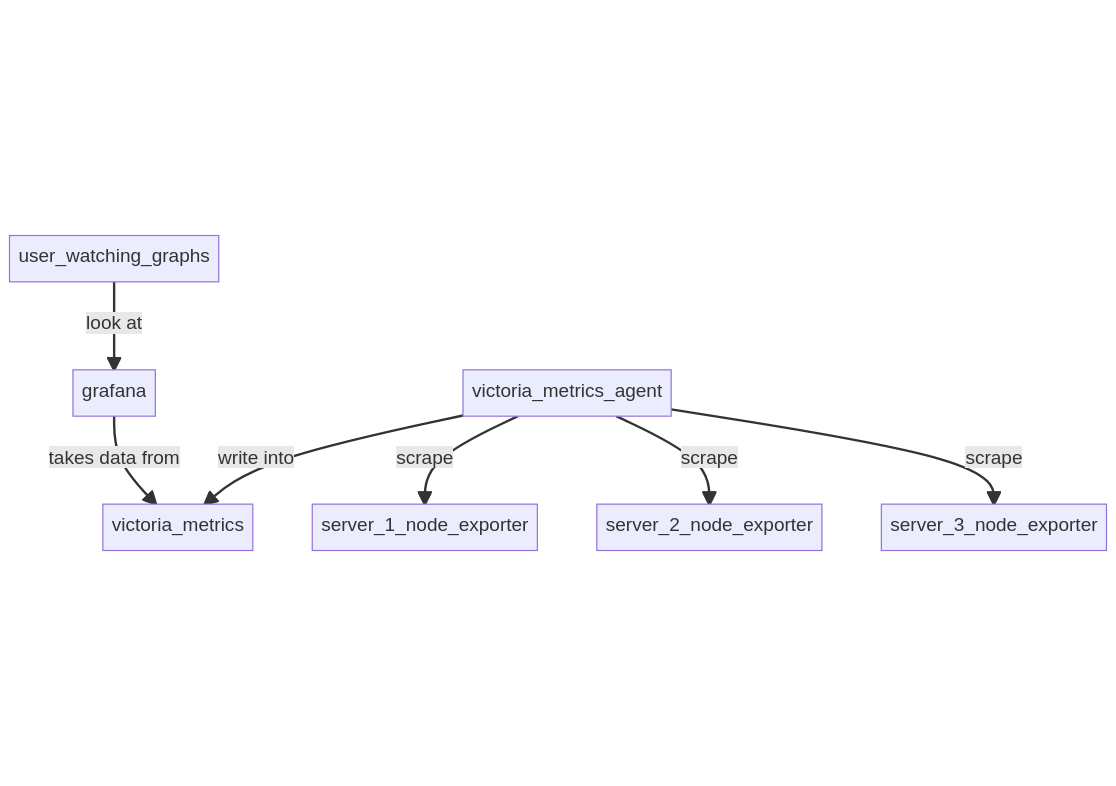
VictoriaMetrics is a Prometheus drop-in replacement that is a lot more efficient (faster and use less resources), which also provides various API such as Graphite or InfluxDB. It's the component storing data. It comes with various programs like VictoriaMetrics agent to replace various parts of Prometheus.
Update: a dear reader shown me VictoriaMetrics can be used to scrape remote agents without the VictoriaMetrics agent, this reduce the memory usage and configuration required.
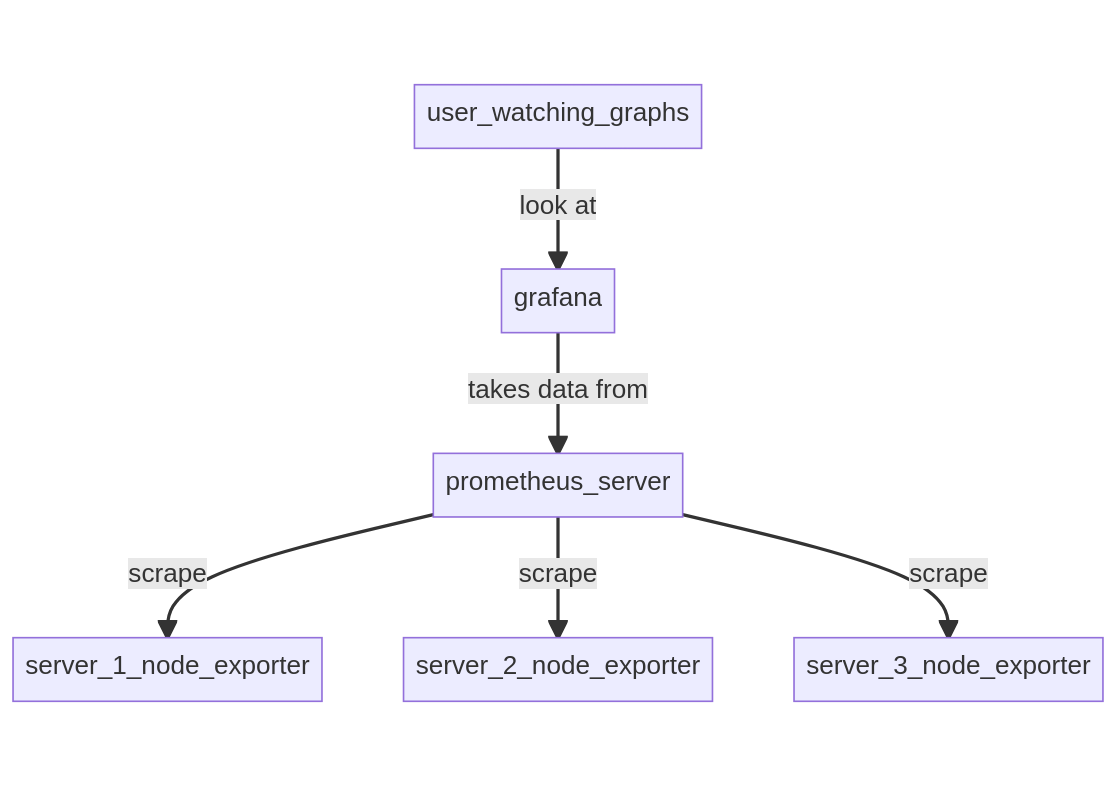
Prometheus is a time series database, which also provide a collecting agent named Node Exporter. It's also able to pull (scrape) data from remote services offering a Prometheus API.
NixOS is an operating system built with the Nix package manager, it has a declarative approach that requires to reconfigure the system when you need to make a change.
4. Setup 2: VictoriaMetrics + node-exporter in pull model §
In this setup, a VictoriaMetrics server is running on a server along with Grafana. A VictoriaMetrics agent is running locally to gather data from remote servers running node_exporter.
Running it on my server, Grafana takes 67 MB, the local node_exporter 12.5 MB, VictoriaMetrics 30 MB and its agent 13.8 MB.
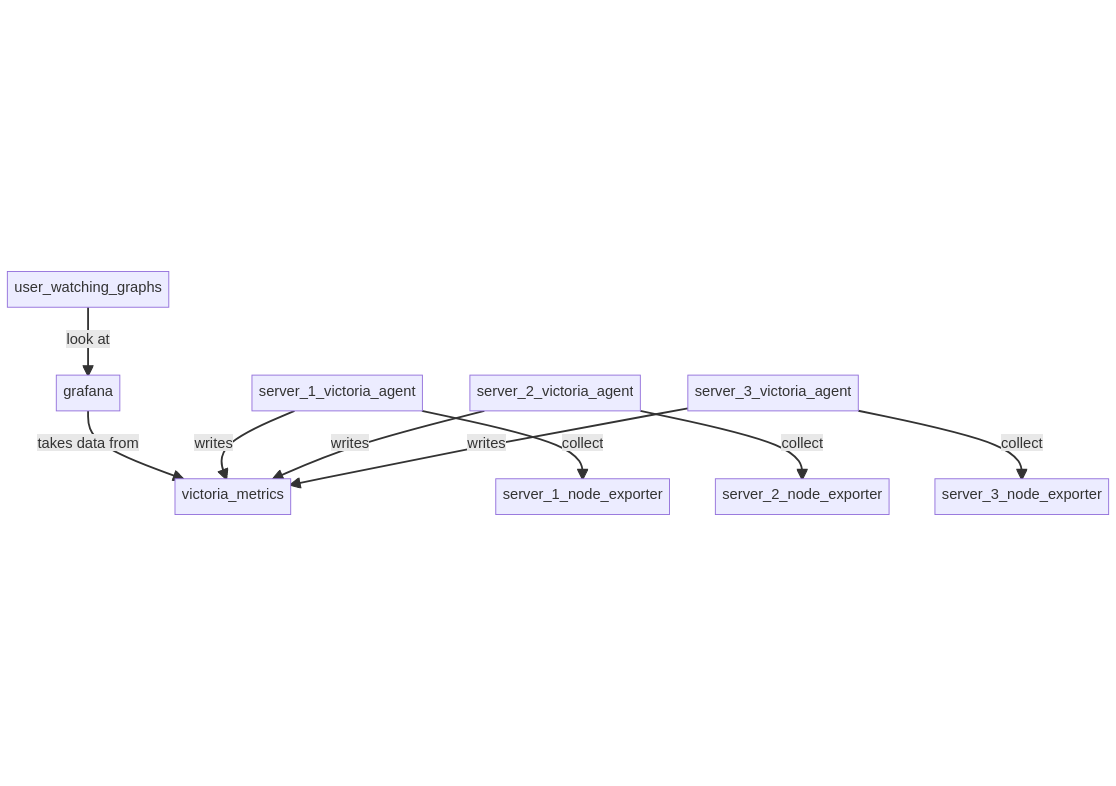
5. Setup 3: VictoriaMetrics + node-exporter in push model §
In this setup, a VictoriaMetrics server is running on a server along with Grafana, on each server node_exporter and VictoriaMetrics agent are running to export data to the central VictoriaMetrics server.
Running it on my server, Grafana takes 67 MB, the local node_exporter 12.5 MB, VictoriaMetrics 30 MB and its agent 13.8 MB, which is exactly the same as the setup 2, except the VictoriaMetrics agent is running on all remote servers.
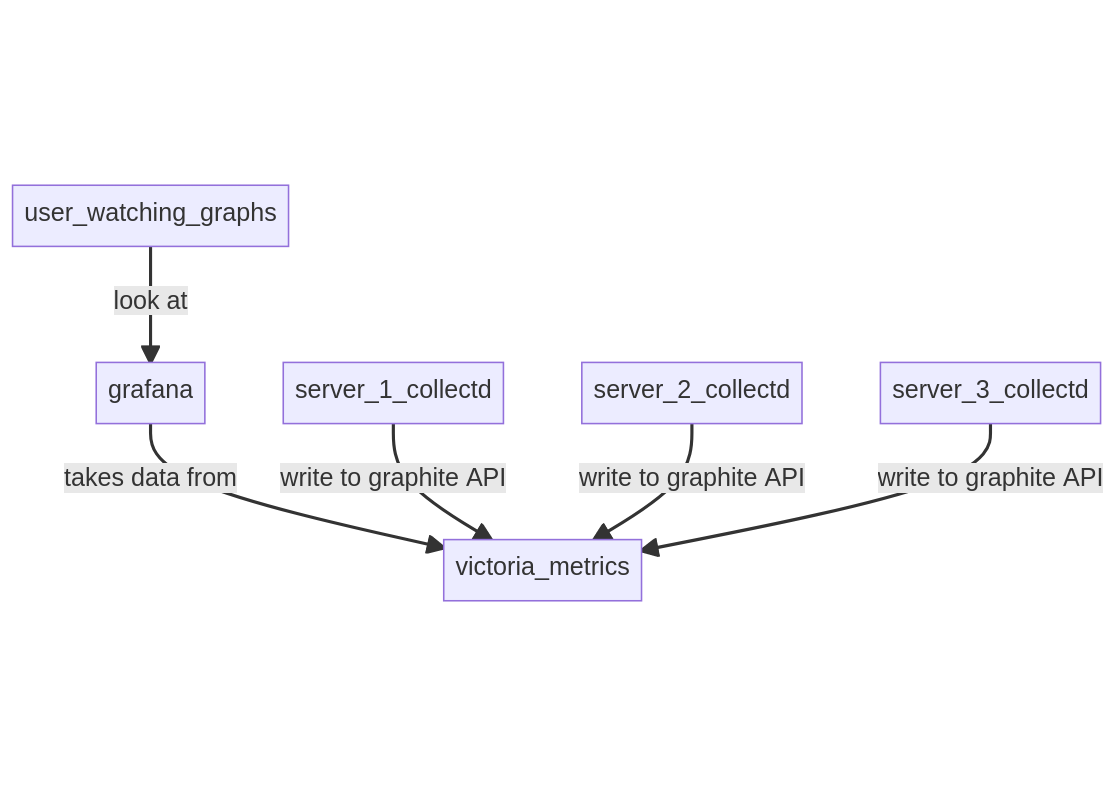
In this setup, a VictoriaMetrics server is running on a server along with Grafana, servers are running Collectd sending data to VictoriaMetrics graphite API.
Running it on my server, Grafana takes 67 MB, VictoriaMetrics 30 MB and Collectd 172 kB (yes).
The server requires VictoriaMetrics to run exposing its graphite API on ports 2003.
Note that in Grafana, you will have to escape "-" characters using "\-" in the queries. I also didn't find a way to automatically discover hosts in the data to use variables in the dashboard.
UPDATE: Using write_tsdb exporter in collectd, and exposing a TSDB API with VictoriaMetrics, you can set a label to each host, and then use the query "label_values(status)" in Grafana to automatic discover hosts.
The first section named #!/bin/introduction" is on purpose and not a mistake. It felt super fun when I started writing the article, and wanted to keep it that way.
The Collectd setup is the most minimalistic while still powerful, but it requires lot of work to make the dashboards and configure the plugins correctly.